В этом руководстве вы узнаете, как использовать функцию VAR() SQL Server для вычисления выборочных дисперсий значений.
Введение в выборочную дисперсию
Дисперсия выборки измеряет, насколько далеко разбросаны наборы чисел от их среднего значения(среднего). Дисперсия выборки позволяет вам получить представление об изменчивости в пределах набора данных выборки.
Чтобы вычислить выборочную дисперсию набора из n чисел, выполните следующие действия:
- Сначала вычислите среднее значение, разделив сумму всех чисел на количество значений в наборе.
- Во-вторых, вычислите сумму разностей квадратов.
- В-третьих, разделите сумму квадратов разностей на количество значений минус один.
Например, если задан набор выборок {1, 2, 3}, можно рассчитать дисперсию выборки следующим образом:
Сначала вычислим среднее значение:
(1 + 2 + 3) / 3 = 2
Во-вторых, вычислите общую квадратную разницу между каждым числом и средним значением:
(1−2)2+(2−2)2+(3−2)2 = 2
В-третьих, вычислите выборочную дисперсию:
2 /(3 – 1) = 1
Дисперсия выборки равна 1.
Агрегатная функция SQL Server VAR()
В SQL Server можно использовать агрегатную функцию VAR() для вычисления выборочной дисперсии набора чисел.
Вот синтаксис функции VAR():
VAR( [ALL | DISTINCT] expression)
В этом синтаксисе:
- ALL: эта опция указывает функции использовать все значения, включая повторяющиеся, для расчета дисперсии выборки.
- DISTINCT: эта опция указывает функции использовать уникальные значения для расчета дисперсии выборки.
Функция VAR() по умолчанию использует опцию ALL. Обратите внимание, что функция VAR() игнорирует NULL.
Функция VAR() возвращает дисперсию выборки как число с плавающей точкой. Она возвращает NULL, если в выборке есть одна или ни одной строки.
Примеры функций VAR() SQL Server
Давайте рассмотрим несколько примеров использования функции VAR() SQL Server.
1) Примеры базовой функции VAR() SQL Server
Сначала создадим таблицу-пример с именем t и одним столбцом id, содержащим несколько чисел 1, 2, 2, 3 и NULL:
CREATE TABLE t(id INT); INSERT INTO t(id) VALUES (1), (2), (2), (3), (NULL); SELECT * FROM t;
Выход:
id ----------- 1 2 2 3 NULL
Во-вторых, вычислите выборочную дисперсию уникальных значений в столбце id таблицы t, используя функцию VAR() с опцией DISTINCT:
SELECT VAR(DISTINCT id) variance FROM t;
Выход:
variance ---------------------- 1 Warning: Null value is eliminated by an aggregate or other SET operation. (1 row affected)
Дисперсия выборки равна 1.
Во-вторых, вычислите выборочную дисперсию всех значений, включая дубликаты в столбце id таблицы t, используя функцию VAR():
variance ---------------------- 0.666666666666667 Warning: Null value is eliminated by an aggregate or other SET operation. (1 row affected)
Дисперсия выборки составляет 0,66666666666667.
2) Практические примеры функции VAR()
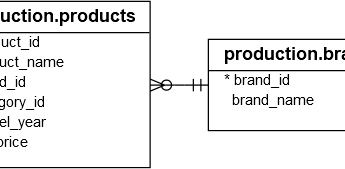
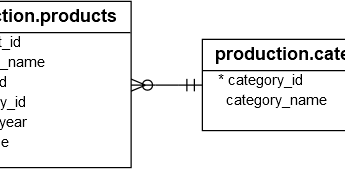
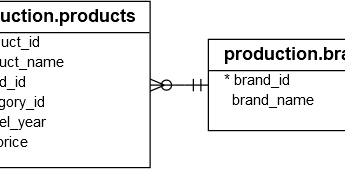
Для демонстрации мы будем использовать таблицы из примера базы данных :
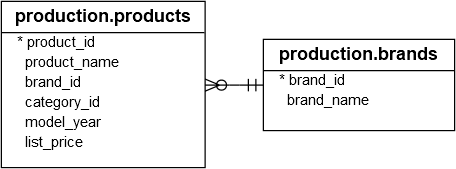
В следующем примере функция VAR() используется для расчета выборочной дисперсии цен прайс-листа бренда с идентификатором 1 и категории с идентификатором 5 в таблице production.products:
SELECT VAR(list_price) var_list_price FROM production.products WHERE brand_id = 1 AND category_id = 5;
Выход:
var_list_price ---------------------- 40000
Чтобы интерпретировать дисперсию выборки, мы можем включить среднюю цену по прейскуранту в набор результатов:
SELECT VAR(list_price) var_list_price, AVG(list_price) avg_list_price FROM production.products WHERE brand_id = 1 AND category_id = 5;
Выход:
var_list_price | avg_list_price ---------------+--------------- 40000.0 | 2799.990000
Дисперсия выборки 40 000,0 означает, что цены на продукты в категории с идентификатором 5 и брендом 1 имеют относительно высокую степень изменчивости вокруг средней цены в 2 799,99.
В следующем примере функция VAR() используется для расчета выборочных дисперсий цен на продукты в категории с идентификатором 1 для каждого бренда:
SELECT b.brand_name, AVG(list_price) avg_list_price, VAR(list_price) var_list_price FROM production.products p INNER JOIN production.brands b ON b.brand_id = p.brand_id WHERE category_id = 1 GROUP BY b.brand_name;
Выход:
brand_name | avg_list_price | var_list_price -------------+----------------+-------------------- Electra | 330.347142 | 3248.015873015962 Haro | 249.990000 | 3199.9999999999905 Strider | 209.990000 | 11200.0 Sun Bicycles | 109.990000 | NULL Trek | 260.424782 | 8040.7114624506585 (5 rows)
Вывод показывает, что:
- Для бренда Sun Bicycles выборочная дисперсия прейскурантной цены равна NULL, поскольку у него есть один продукт с прейскурантной ценой 109,99, как указано в столбце avg_list_price.
- Бренд Strider имеет самую высокую степень изменчивости вокруг средней цены в 209,99 по сравнению с другими брендами.
- У брендов Electra, Haro и Trek разброс цен относительно их средних значений меньше по сравнению с другими брендами.
Краткое содержание
- Используйте функцию VAR() для расчета выборочных дисперсий значений.