В этом уроке вы узнаете, как использовать предложение GROUP BY или функцию ROW_NUMBER() для поиска повторяющихся значений в таблице.
Технически вы используете ограничения UNIQUE для обеспечения уникальности строк в одном или нескольких столбцах таблицы. Однако иногда вы можете обнаружить дублирующиеся значения в таблице из-за плохого дизайна базы данных, ошибок приложения или неочищенных данных из внешних источников. Ваша задача — эффективно идентифицировать эти дублирующиеся значения.
Чтобы найти повторяющиеся значения в таблице, выполните следующие действия:
- Сначала определите критерии дубликатов: значения в одном столбце или в нескольких столбцах.
- Во-вторых, напишите запрос для поиска дубликатов.
Если вы также хотите удалить дубликаты строк, вы можете перейти к руководству по удалению дубликатов из таблицы.
Давайте создадим пример таблицы для демонстрации.
Создание таблицы образцов
Сначала создайте новую таблицу с именем t1, содержащую три столбца id, a и b.
DROP TABLE IF EXISTS t1;
CREATE TABLE t1(
id INT IDENTITY(1, 1),
a INT,
b INT,
PRIMARY KEY(id)
);
Затем вставьте несколько строк в таблицу t1:
INSERT INTO
t1(a,b)
VALUES
(1,1),
(1,2),
(1,3),
(2,1),
(1,2),
(1,3),
(2,1),
(2,2);
Таблица t1 содержит следующие повторяющиеся строки:
(1,2) (2,1) (1,3)
Ваша цель — написать запрос для поиска указанных выше дубликатов строк.
Использование предложения GROUP BY для поиска дубликатов в таблице
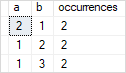
В этом операторе используется предложение GROUP BY для поиска дубликатов строк в столбцах a и b таблицы t1:
SELECT
a,
b,
COUNT(*) occurrences
FROM t1
GROUP BY
a,
b
HAVING
COUNT(*) > 1;
Вот результат:
Как это работает:
- Во-первых, предложение GROUP BY группирует строки в группы по значениям в столбцах a и b.
- Во-вторых, функция COUNT() возвращает количество вхождений каждой группы(a,b).
- В-третьих, предложение HAVING сохраняет только дублирующиеся группы, то есть группы, которые встречаются более одного раза.
Чтобы вернуть всю строку для каждой дублирующей строки, необходимо объединить результат приведенного выше запроса с таблицей t1, используя общее табличное выражение( CTE ):
WITH cte AS(
SELECT
a,
b,
COUNT(*) occurrences
FROM t1
GROUP BY
a,
b
HAVING
COUNT(*) > 1
)
SELECT
t1.id,
t1.a,
t1.b
FROM t1
INNER JOIN cte ON
cte.a = t1.a AND
cte.b = t1.b
ORDER BY
t1.a,
t1.b;
Вот что получилось:

Обычно запрос для поиска повторяющихся значений в одном столбце с использованием предложения GROUP BY выглядит следующим образом:
SELECT
col,
COUNT(col)
FROM
table_name
GROUP BY
col
HAVING
COUNT(col) > 1;
Запрос для поиска повторяющихся значений в нескольких столбцах с использованием предложения GROUP BY:
SELECT
col1,col2,...
COUNT(*)
FROM
table_name
GROUP BY
col1,col2,...
HAVING
COUNT(*) > 1;
Использование функции ROW_NUMBER() для поиска дубликатов в таблице
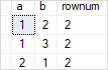
Следующий оператор использует функцию ROW_NUMBER() для поиска повторяющихся строк на основе столбцов a и b:
WITH cte AS(
SELECT
a,
b,
ROW_NUMBER() OVER(
PARTITION BY a,b
ORDER BY a,b) rownum
FROM
t1
)
SELECT
*
FROM
cte
WHERE
rownum > 1;
Вот результат:
Как это работает:
Сначала ROW_NUMBER() распределяет строки таблицы t1 по разделам по значениям в столбцах a и b. Дублирующиеся строки будут иметь повторяющиеся значения в столбцах a и b, но разные номера строк, как показано на следующем рисунке:
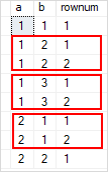
Во-вторых, внешний запрос удаляет первую строку в каждой группе.
Как правило, этот оператор использует функцию ROW_NUMBER() для поиска повторяющихся значений в одном столбце таблицы:
WITH cte AS(
SELECT
col,
ROW_NUMBER() OVER(
PARTITION BY col
ORDER BY col) row_num
FROM
t1
)
SELECT * FROM cte
WHERE row_num > 1;
В этом руководстве вы узнали, как использовать предложение GROUP BY или функцию ROW_NUMBER() для поиска повторяющихся значений в SQL Server.