В этом руководстве вы узнаете, как использовать оператор SQL Server CREATE INDEX для создания некластеризованных индексов для таблиц.
- Введение в некластеризованные индексы SQL Server
- SQL Server оператор CREATE INDEX
- Примеры операторов SQL Server CREATE INDEX
- 1) Использование оператора CREATE INDEX для создания некластеризованного индекса для примера с одним столбцом
- 2) Использование оператора CREATE INDEX для создания некластеризованного индекса для нескольких столбцов
- Краткое содержание
Введение в некластеризованные индексы SQL Server
Некластеризованный индекс — это структура данных, которая повышает скорость извлечения данных из таблиц. В отличие от кластеризованного индекса, некластеризованный индекс сортирует и хранит данные отдельно от строк данных в таблице. Это копия выбранных столбцов данных из таблицы со ссылками на связанную таблицу.
Как и кластеризованный индекс, некластеризованный индекс использует структуру B-дерева для организации своих данных.
Таблица может иметь один или несколько некластеризованных индексов, и каждый некластеризованный индекс может включать один или несколько столбцов в таблице.
На следующем рисунке показана структура некластеризованного индекса:
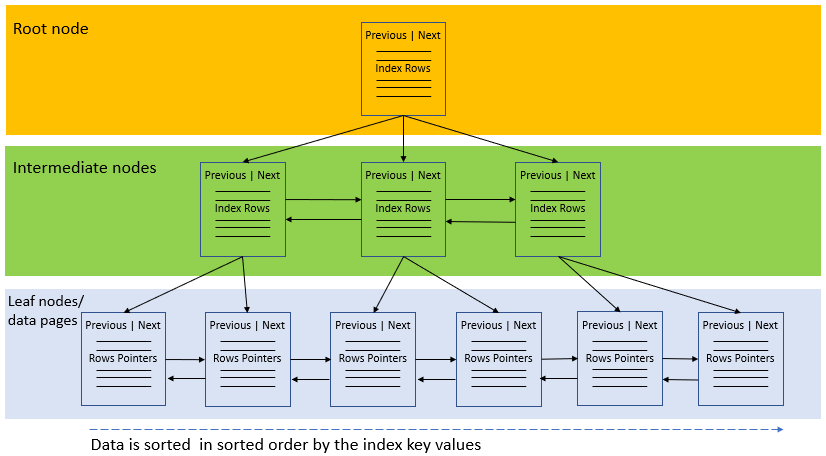
Помимо хранения значений индексных ключей, листовые узлы также хранят указатели строк на строки данных, содержащие значения ключей. Эти указатели строк также известны как локаторы строк.
Если базовая таблица является кластеризованной таблицей, указатель строки является кластеризованным ключом индекса. В случае, если базовая таблица является кучей, указатель строки указывает на строку таблицы.
SQL Server оператор CREATE INDEX
Для создания некластеризованного индекса используйте оператор CREATE INDEX:
CREATE [NONCLUSTERED] INDEX index_name ON table_name(column_list);
В этом синтаксисе:
- Сначала укажите имя индекса после предложения CREATE NONCLUSTERED INDEX. Обратите внимание, что ключевое слово NONCLUSTERED является необязательным.
- Во-вторых, укажите имя таблицы, для которой вы хотите создать индекс, и список столбцов этой таблицы в качестве ключевых столбцов индекса.
Примеры операторов SQL Server CREATE INDEX
Для демонстрации мы будем использовать sales.customers из образца базы данных.

Таблица sales.customers является кластеризованной таблицей, поскольку имеет первичный ключ customer_id.
1) Использование оператора CREATE INDEX для создания некластеризованного индекса для примера с одним столбцом
В этом заявлении указаны клиенты, проживающие в Атуотере:
SELECT
customer_id,
city
FROM
sales.customers
WHERE
city = 'Atwater';
Если вы отобразите предполагаемый план выполнения, вы увидите, что оптимизатор запросов сканирует кластеризованный индекс, чтобы найти строку. Это происходит потому, что таблица sales.customers не имеет индекса для столбца city.

Чтобы повысить скорость выполнения этого запроса, вы можете создать новый индекс с именем ix_customers_city для столбца города:
CREATE INDEX ix_customers_city ON sales.customers(city);
Теперь, если вы снова отобразите предполагаемый план выполнения приведенного выше запроса, вы обнаружите, что оптимизатор запросов использует некластеризованный индекс ix_customers_city:

2) Использование оператора CREATE INDEX для создания некластеризованного индекса для нескольких столбцов
Следующее выражение находит клиента с фамилией Берг и именем Моника:
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
last_name = 'Berg' AND
first_name = 'Monika';

Оптимизатор запросов сканирует кластеризованный индекс, чтобы найти клиента.
Чтобы ускорить извлечение данных, можно создать некластеризованный индекс, включающий столбцы last_name и first_name:
CREATE INDEX ix_customers_name ON sales.customers(last_name, first_name);
Теперь оптимизатор запросов использует индекс ix_customers_name для поиска клиента.
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
last_name = 'Berg' AND
first_name = 'Monika';

При создании некластеризованного индекса, состоящего из нескольких столбцов, порядок столбцов в индексе очень важен. Вам следует поместить столбцы, которые вы часто используете для запроса данных, в начало списка столбцов.
Например, следующий оператор находит клиентов с фамилией Альберт. Поскольку last_name — это самый левый столбец в индексе, оптимизатор запросов может использовать индекс и использовать метод поиска по индексу для поиска:
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
last_name = 'Albert';

Этот оператор находит клиентов, чье имя — Адам. Он также использует индекс ix_customer_name. Но для поиска ему нужно сканировать весь индекс, что медленнее, чем поиск по индексу.
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
first_name = 'Adam';

Поэтому рекомендуется размещать столбцы, которые вы часто используете для запроса данных, в начале списка столбцов индекса.
Краткое содержание
- Некластеризованный индекс копирует данные таблицы и сохраняет их в отдельной структуре данных(B-дереве).
- Таблица может иметь несколько некластеризованных индексов.
- Используйте оператор CREATE INDEX для создания некластеризованного индекса с целью повышения скорости выполнения запросов.