В этом руководстве вы узнаете о кластеризованном индексе SQL Server и о том, как определить кластеризованный индекс для таблицы.
Введение в кластеризованные индексы SQL Server
Следующий оператор создает новую таблицу с именем production.parts, состоящую из двух столбцов part_id и part_name:
CREATE TABLE production.parts(
part_id INT NOT NULL,
part_name VARCHAR(100)
);
А этот оператор вставляет несколько строк в таблицу production.parts:
INSERT INTO
production.parts(part_id, part_name)
VALUES
(1,'Frame'),
(2,'Head Tube'),
(3,'Handlebar Grip'),
(4,'Shock Absorber'),
(5,'Fork');
Таблица production.parts не имеет первичного ключа. Поэтому SQL Server хранит свои строки в неупорядоченной структуре, называемой кучей.
При запросе данных из таблицы production.parts оптимизатору запросов необходимо просканировать всю таблицу для поиска.
Например, следующий оператор SELECT находит деталь с идентификатором 5:
SELECT
part_id,
part_name
FROM
production.parts
WHERE
part_id = 5;
Если вы отобразите предполагаемый план выполнения в SQL Server Management Studio, вы увидите, как SQL Server составил следующий план запроса:

Обратите внимание, что для отображения предполагаемого плана выполнения в SQL Server Management Studio нажмите кнопку «Отобразить предполагаемый план выполнения» или выберите запрос и нажмите сочетание клавиш Ctrl+L:

Поскольку таблица production.parts содержит всего пять строк, запрос выполняется очень быстро. Однако, если таблица содержит большое количество строк, то поиск данных займет много времени и ресурсов.
Для решения этой проблемы SQL Server предоставляет специальную структуру для ускорения извлечения строк из таблицы, называемую индексом.
SQL Server имеет два типа индексов: кластеризованный индекс и некластеризованный индекс. В этом руководстве мы сосредоточимся на кластеризованном индексе.
Кластеризованный индекс хранит строки данных в отсортированной структуре на основе ее ключевых значений. Каждая таблица имеет только один кластеризованный индекс, поскольку строки данных могут быть отсортированы только в одном порядке. Таблица, имеющая кластеризованный индекс, называется кластеризованной таблицей.
На следующем рисунке показана структура кластеризованного индекса:
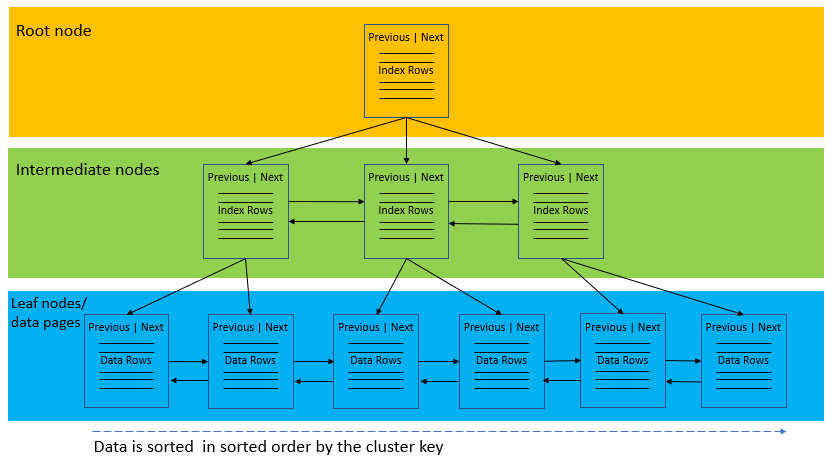
Кластеризованный индекс организует данные с помощью специального структурированного так называемого B-дерева(или сбалансированного дерева), которое позволяет выполнять поиск, вставку, обновление и удаление за логарифмическое амортизированное время.
В этой структуре верхний узел B-дерева называется корневым узлом. Узлы на нижнем уровне называются листовыми узлами. Любые уровни индекса между корневым и листовыми узлами называются промежуточными уровнями.
В B-Tree корневой узел и узлы промежуточного уровня содержат страницы индекса, которые содержат строки индекса. Листовые узлы содержат страницы данных базовой таблицы. Страницы на каждом уровне индекса связаны с помощью другой структуры, называемой двусвязным списком.
Кластеризованный индекс SQL Server и ограничение первичного ключа
При создании таблицы с первичным ключом SQL Server автоматически создает соответствующий кластеризованный индекс, включающий столбцы первичного ключа.
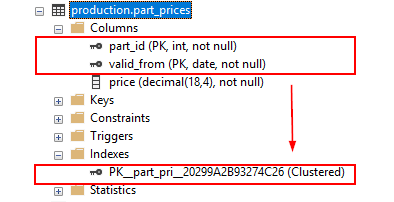
Этот оператор создает новую таблицу с именем production.part_prices с первичным ключом, включающим два столбца: part_id и valid_from.
CREATE TABLE production.part_prices(
part_id int,
valid_from date,
price decimal(18,4) not null,
PRIMARY KEY(part_id, valid_from)
);
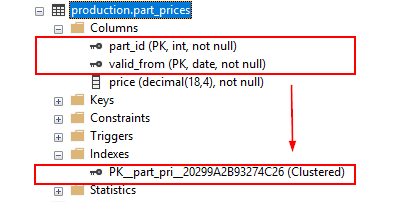
Если вы добавите ограничение первичного ключа к существующей таблице, которая уже имеет кластеризованный индекс, SQL Server применит первичный ключ, используя некластеризованный индекс:
Этот оператор определяет первичный ключ для таблицы production.parts:
ALTER TABLE production.parts ADD PRIMARY KEY(part_id);
SQL Server создал некластеризованный индекс для первичного ключа.
Использование оператора SQL Server CREATE CLUSTERED INDEX для создания кластеризованного индекса.
Если таблица не имеет первичного ключа, что случается очень редко, можно использовать оператор CREATE CLUSTERED INDEX, чтобы добавить к ней кластеризованный индекс.
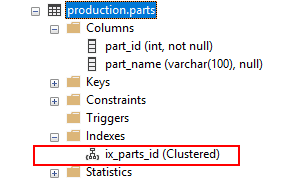
Следующий оператор создает кластеризованный индекс для таблицы production.parts:
CREATE CLUSTERED INDEX ix_parts_id ON production.parts(part_id);
Если вы откроете узел «Индексы» под именем таблицы, вы увидите новое имя индекса ix_parts_id с типом «Кластеризованный».
При выполнении следующего оператора SQL Server просматривает индекс(поиск по кластеризованному индексу) для поиска строк, что быстрее, чем сканирование всей таблицы.
SELECT
part_id,
part_name
FROM
production.parts
WHERE
part_id = 5;

Синтаксис SQL Server CREATE CLUSTERED INDEX
Синтаксис создания кластеризованного индекса следующий:
CREATE CLUSTERED INDEX index_name ON schema_name.table_name(column_list);
В этом синтаксисе:
- Сначала укажите имя кластеризованного индекса после предложения CREATE CLUSTERED INDEX.
- Во-вторых, укажите схему и имя таблицы, на основе которой вы хотите создать индекс.
- В-третьих, перечислите один или несколько столбцов, включенных в индекс.
Краткое содержание
- Кластерный индекс физически организует данные в таблице в соответствии с ключом индекса.
- При создании таблицы с первичным ключом SQL Server автоматически создает кластеризованный индекс на основе столбцов первичного ключа.
- Таблица имеет только один кластеризованный индекс.
- Используйте оператор CREATE CLUSTERED INDEX для создания нового кластеризованного индекса для таблицы.